The Battle of the Compressors: Optimizing Spark Workloads with
Hello! Hope you’re having a wonderful time working with challenging issues around Data and Data Engineering. In this article let’s look at the different compression algorithms Apache Spark offers…

Spark on Scala: Adobe Analytics Reference Architecture, by Adrian Tanase

Big Data with Spark and Scala. Big Data is a new term that is used…, by Jidnasa Pillai

The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet, by Siraj
Optimizing genomic data processing on Apache Spark, by Johan Nyström-Persson
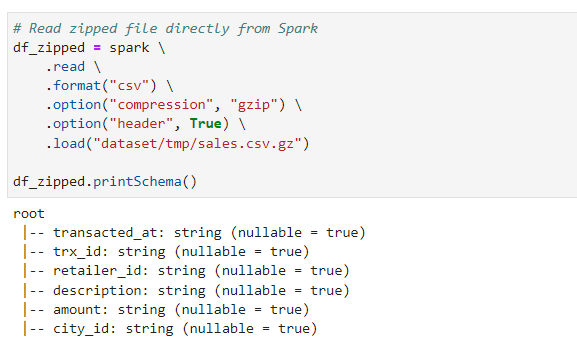
PySpark — Read Compressed gzip files, by Subham Khandelwal

Spark + Cassandra, All You Need to Know: Tips and Optimizations, by Javier Ramos
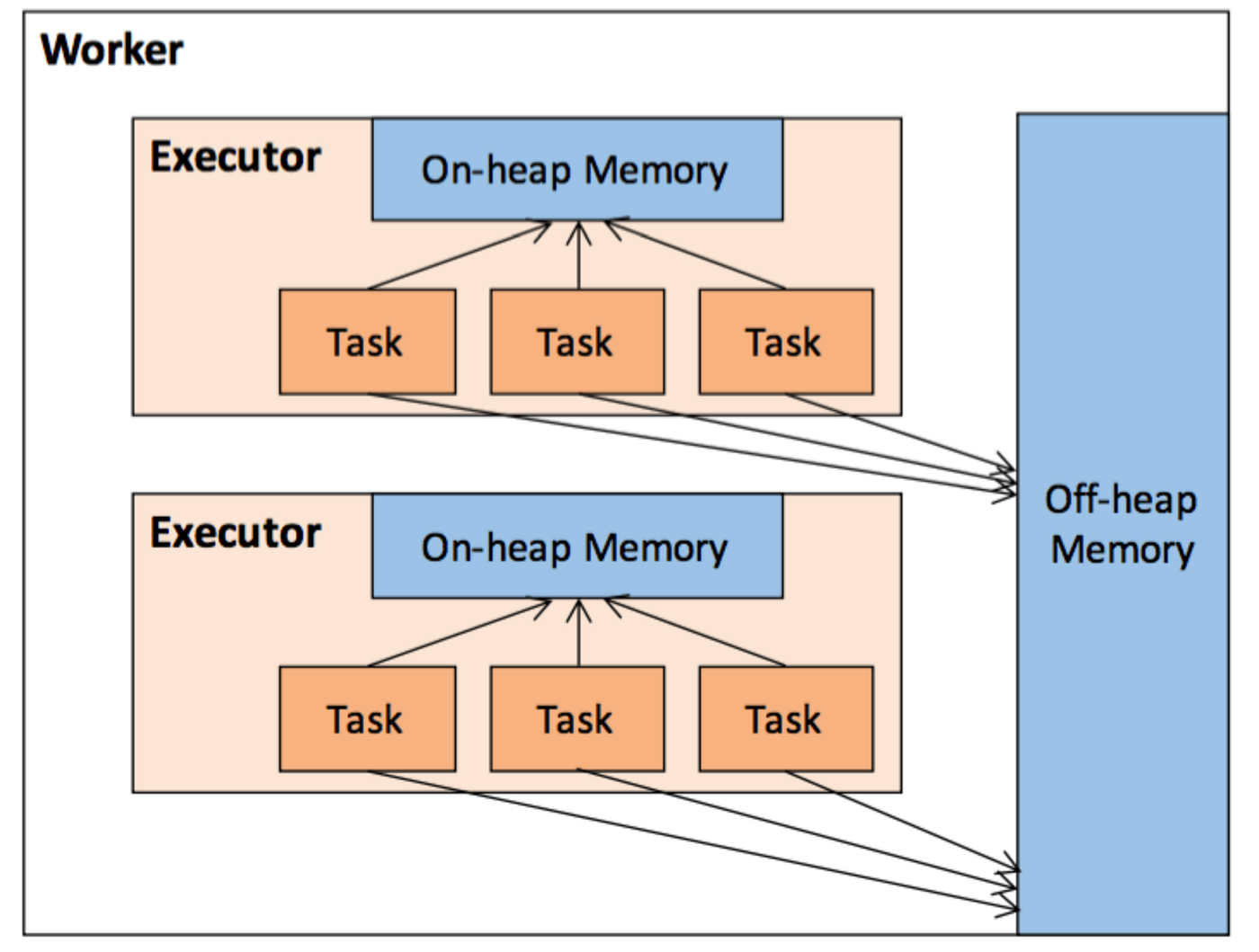
Spark On-Heap and Off Heap Memory, by Nethaji Kamalapuram

Dicom Read Library (Apache Spark Third-Party Contribution), by BigData & Cloud Practice

Bharanidharan muthukumar on LinkedIn: Databricks Certified Associate Developer for Apache Spark 3.0 •…




.jpg?f=webp&q=85)

